This appendix describes only those enhancements made to the COBOL programming language for writing programs that process double-byte characters. Double byte implies that for every character a fixed width sequence of two bytes is used distinguishing about 65000 characters.
Os 2 And Multilingual Character Sets Part 2 Edm2

Here is my attempt to do this with a double byte character set.

Double byte character sets. Each byte is evaluated separately and gives the character back for that byte individually. Specifically this appendix describes where you can use Double-Byte Character Set DBCS characters in each portion of a COBOL program and considerations for working with DBCS data in the ILE COBOL language. To create coded character sets for such languages the.
By definition character set A is a superset of character set B if A supports all characters. The difference between DBCS and SBCS is the number of bytes the computer uses to represent the character. Punctuation alphabets numbers Kana Kanji 213 Character set 0x7A row number 90 traffic symbols.
The problem is the output file still only contains the first 255 characters. DBCS meant that you need to write code that would treat these pair of code points as one. This support is available for sensitive information types and keyword dictionaries and will be reflected in data loss prevention for Exchange Online SharePoint Online OneDrive for Business and Teams Communications Compliance Auto Labelling in office.
So if I have a DBCS string MOTH it is 4 characters and LENMOTH will give an answer of 4. 21 Kanji double-byte set 211 Lead byte 212 Character sets 0x21-0x74 row numbers 1-84. Multibyte character sets are available for use with Uniface.
Double-byte character set fundamentals Some languages such as Chinese Japanese and Korean have a writing scheme that uses many different characters that cannot be represented with single-byte codes. It takes two bytes to assign a code point to each character ie it represents each character with 2 bytes. Both ASCII and EBCDIC are single-byte codes.
The number of characters in a string is not related to whether that string is DBCS or SBCS. Languages that use double-byte character sets include Chinese Japanese and Korean. Only connectors for databases that support double-byte data need to be changed.
Double byte implies that for every character a fixed width sequence of two bytes is used distinguishing about 65000 characters. This was the case with a primitive type of Unicode encoding called UCS-2 used on older Microsoft platforms. A double-byte character set is a character set that uses 2-byte 16-bit characters instead of 1-byte 8-bit characters.
A Double Byte Character Set is a character set where. The double-byte character set DBCS is called an expanded 8-bit character set because its smallest unit is a byte. DBCSs were originally developed to extend the SBCS design to.
Double-Byte Character Sets This document is only relevant for Asian countries which use double-byte character sets. The terms subset and superset without the adjective binary pertain to character repertoires of two Oracle character sets that is to the sets of characters supported encoded by each of the character sets. Even in early computing however this number was already recognized to be insufficient.
A DBCS can be thought of as the ANSI character set for some Asian versions of Microsoft Windows particularly the Japanese versions. Actually though still widely used the term double-byte is obsolete. A double-byte character set DBCS also known as an expanded 8-bit character set is an extended single-byte character set SBCS implemented as a code page.
Even in early computing however this number was already recognized to be insufficient. Chinese Japanese and Korean require a double byte character set that is not listed here. Some languages use characters that cannot be represented by using single-byte codes.
In a single byte character set there are 256 codes from 0 to 255. Some characters in a DBCS have a single byte code value and some have a double byte code value. The output file will contain Japanese characters such as .
Microsoft 365 Information Protection now supports double byte character set languages for. Character sets which use double bytes to represent their characters are referred to as a double-byte character set DBCS. This was the case with a primitive type of Unicode encoding called UCS-2 used on older Microsoft platforms.
It describes all features implemented in Natural to support DBCS terminals and printers. Character data truncation can occur when the number of bytes for a character in one encoding is different from the number of bytes for the same character in another encoding such as when a single-byte character set SBCS is transcoded to a double-byte character set DBCS or. 83 rows Double-Byte Character Sets DBCSs use one or two bytes to represent each character and.
1 for Single Byte CS 2 for Double Byte CS.

Character Set Encoding Basics
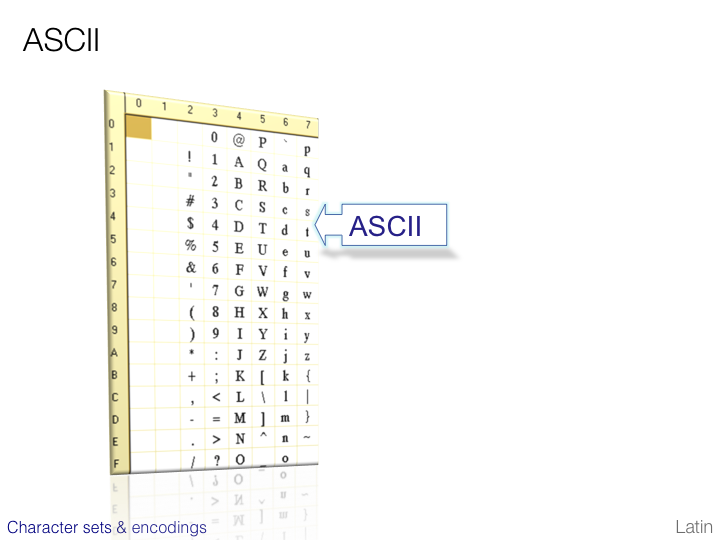
An Introduction To Writing Systems

Choosing A Character Set
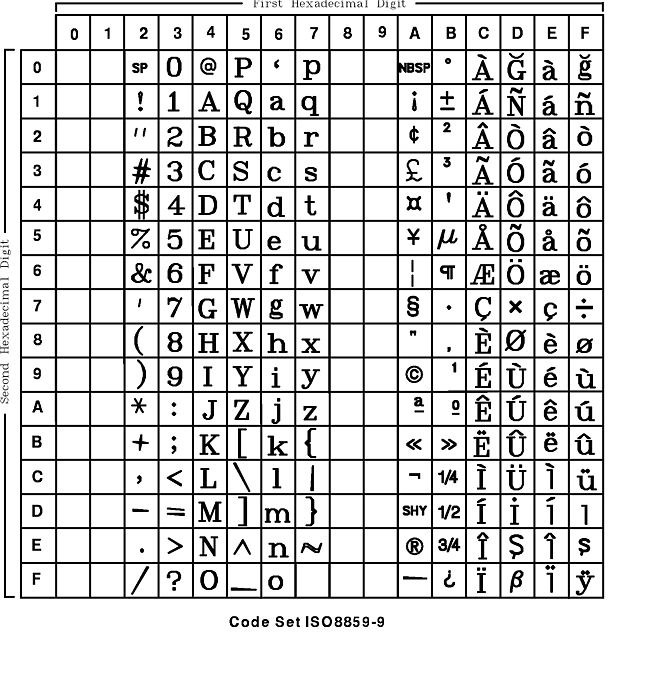
Code Set Overview
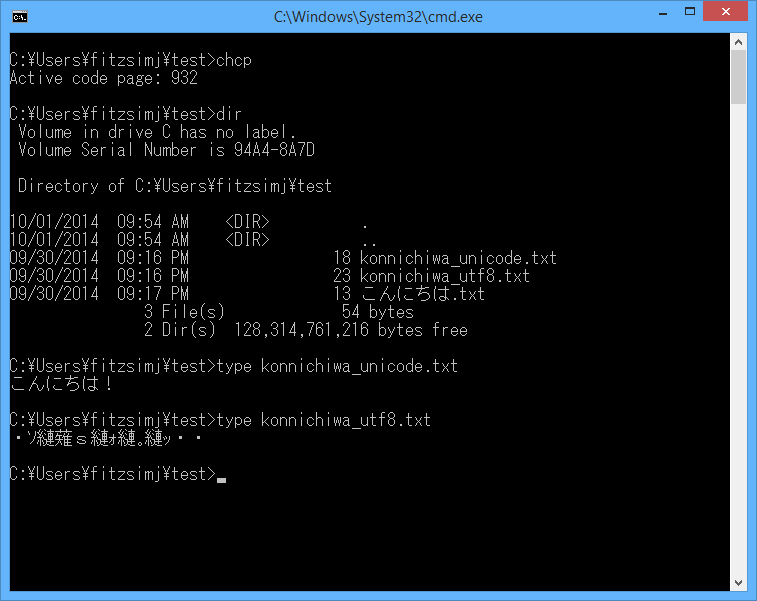
Windows Console And Double Multi Byte Character Set Words
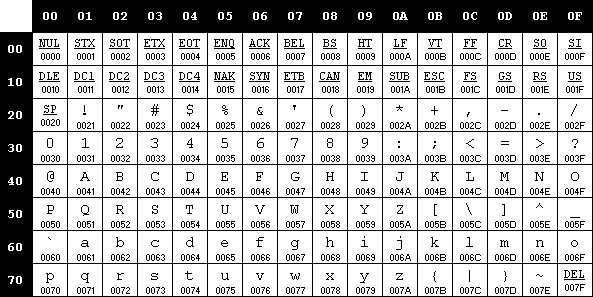
Traditional Character Encoding Developing International Software

Choosing A Character Set

The Dbcs Function Article Blog Sumproduct Are Experts In Excel Training Financial Modelling Strategic Data Modelling Model Auditing Planning Strategy Training Courses Tips Online Knowledgebase
Index Of Charsets
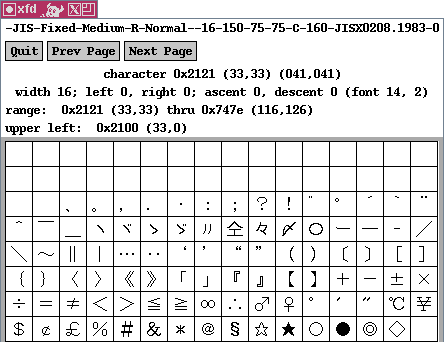

Choosing A Character Set
Os 2 And Multilingual Character Sets Part 2 Edm2

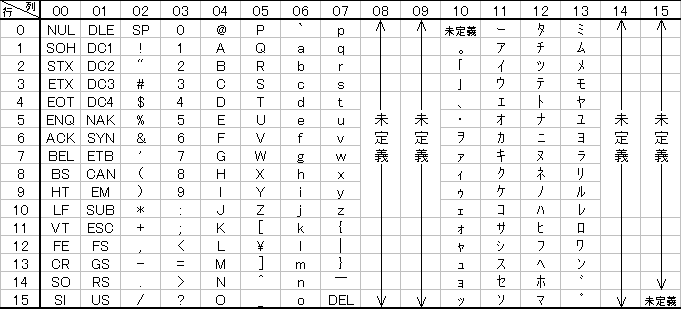
Encodings Of Japanese
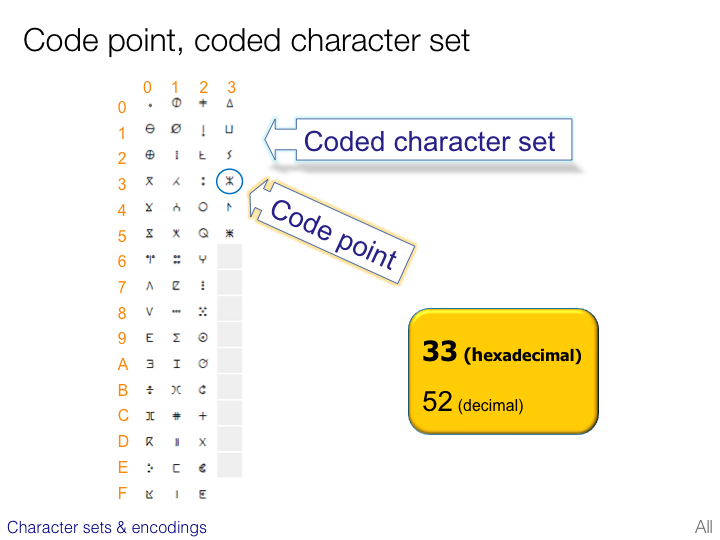
An Introduction To Writing Systems

An Introduction To Writing Systems

Choosing A Character Set
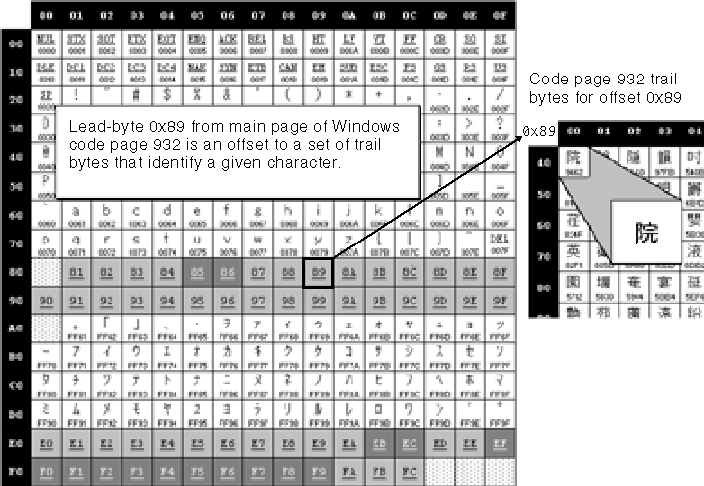
Traditional Character Encoding Developing International Software
C H A P T E R 14 Enabling Dbcs Support
Character Encoding Im Tx


Double Byte Characters Are Displayed As Question Mark Sqlhints Com

